
PDF (Portable Document Format) is one of the most convenient file formats we use in our daily lives.
By converting text and other content to PDF, you can
・Compress the size of the original file
・Protect the contents of the original file so that it cannot be rewritten
・Easy to browse and search from your PC or smartphone
and so on…
So, in this article, we will show you how to manipulate PDF documents with Python.
By combining “the Convenience and Versatility of PDF” with “the Scalability, data analysis, and processing capabilities of Python”, you will be able to further expand the range of your applications.

Working with PDF files from Python requires installing and importing an external library.
There are several libraries that manipulate PDF, including PDFMiner, PyPDF2, and ReportLab.
However, since PDF is a very complex specification, it seems that a single library cannot cover all PDF’s functions. Therefore, each library has different features and specialties.
Users need to use them differently or combine them according to purpose.
The following is a rough guideline for “How to use different types according to the purpose and characteristics? Please refer to it.

In this article, we would like to illustrate how to extract text contents from PDF files using “PDFMiner” among these libraries.
It is also assumed that the package management software <Anaconda> has already been installed in the development environment.
The development environment and version information checked in this article are as follows. Please keep this in mind when using different environments and versions.
1. PDFMiner Overview and Introduction

First, we will organize an overview of PDFMiner, a library for manipulating PDF.
PDFMiner seems to be good at extracting text, but it can also extract other contents that make up PDF, such as images (JPG, Bitmap), tables, and bookmarks.
It supports Japanese, Chinese, and Korean languages, and can handle vertically written text.
Also, depending on the generation of Python, it is divided into the following versions.
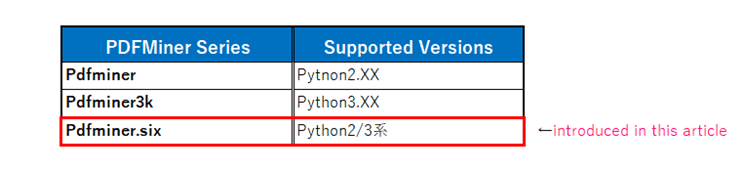
In this article, we will explain how to use “pdfminer.six“, which is Python 3.x and can be easily installed using the package management command pip.
The usage of the classes introduced in this site is just an example. Optional arguments are omitted. Please refer to the official documentation for details and clarifications as necessary.
【Official Document】:https://pdfminersix.readthedocs.io/en/latest/
1.1 Installation and Aperation check
The pdfminer.six is not bundled with Anacoda and must be installed separately using pip, etc. Enter the following command at the Anaconda prompt to install it.
pip install pdfminer.sixNext, let’s check to see if it was installed successfully.
As described below, there are many modules in pdfminer.six, so choose one of them and load it. For example, try importing and executing the PDFResourceManager class from the pdfminer.pdfinterp module. If no error messages are displayed, the install has been successful.
from pdfminer.pdfinterp import PDFResourceManager
rmgr = PDFResourceManager()2. Class required for Text Extraction

The PDF file specification has a complex structure, so just extracting text using “pdfminer.six” requires importing five classes. In summary, the following classes are required.

The correlation diagram between objects acquired from each class is as follows. (Fig.2) The “PDFResorceManager object” manages all content (text and images) in PDF and interacts with other objects. Finally, the “PDFPageInterpreter object” is used to perform parsing and text extraction. The flow shown in Figure 2 is complicated, but it is worth remembering as a common practice when using pdfminer.six.
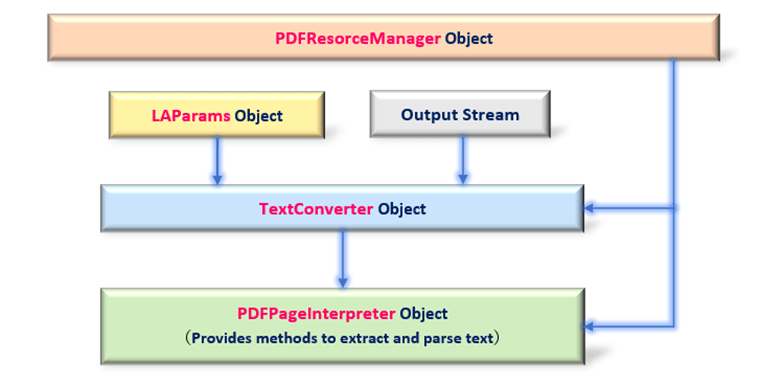
From the next section, class specifications for acquiring various objects will be explained.
2.1 Get PDFResourceManager Object
The PDFResourceManager class is the core class for managing content (text, images, etc.) and other resources in PDF.
To manipulate PDF in Pdfminer.six, the first step is to get a “PDFResourceManager object”.
from pdfminer.pdfinterp import PDFResourceManager
PDFResourceManager()
return: PDFResourceManager Object
2.2 Get LAParams Object
The LAParams class is used to set the PDF file layout information required for text analysis as a parameter.
In this article, all the default settings (no arguments) are used for analysis. If you wish to extract vertical characters or text within a shape, set the appropriate settings.
from pdfminer.layout import LAParams
LAParams(line_overlap, char_margin, detect_vertical, all_texts)
arg: line_overlap:
Value that determines whether or not a word can be split at a line break (Default:0.5)
arg: char_margin: Spacing between words (Default:2.0)
arg: detect_vertical: Whether to allow vertical character parsing (Default:False)
arg: all_texts: Whether to parse text within a shape (Default:False)
return: LAParams Object
Many other optional arguments
2.3 Get TextConverter Object
The TextConverter class provides the ability to extract text in PDF.
Set <2.1 PDFResourceManager object> for the arg:rsrcmgr and <2.2 LAParams object> for the arg:laparams. The output destination for text parsed and extracted by pdfminer is the Python console or a file. The output stream is passed to arg:outfp.
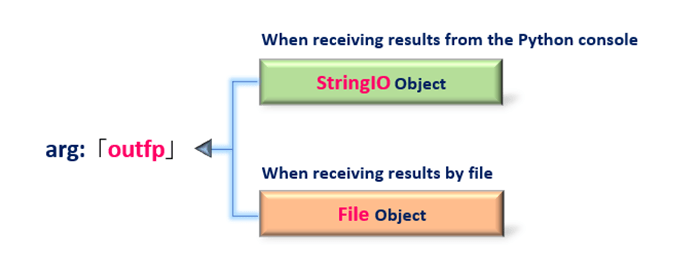
from pdfminer.converter import TextConverter
TextConverter(rsrcmgr, outfp, laparams)
arg1: rsrcmgr: Set PDFResourceManager Object
arg2: outfp: Set the Output Stream Object
arg3: laparams: Set the LAParams Object
return: TextConverter Object
2.4 Get PDFPage Object
The PDFPage class generates a generator that retrieves individual information for each page from a PDF. Usually, the get_pages() and create_pages() methods are also used to get a PDFPage object.
However, the objects passed to these two methods are different. The former takes a File object pointing to the PDF to be parsed, and the latter takes a PDFDcument object (see below) as an argument.
from pdfminer.pdfpage import PDFPage
PDFPage.get_pages(fp, password)
arg1:fp : Set the file object of the PDF to be analyzed
arg2:password: Set password (optional), Specify with string
return: PDFPage Object
PDFPage.create_pages(doc)
arg:doc: Specify PDFDocument object
return: PDFPage Object
2.5 Get PDFPageInterpreter Object
The PDFPageInterpreter class provides the ability to analyze acquired PDFPage objects.
Set <2.1 PDFResourceManager Object> for arg:rsrcmgr and <2.3 TextConverter Object> for arg:device.
from pdfminer.pdfinterp import PDFPageInterpreter
PDFPageInterpreter(rsrcmgr, device)
arg1: rsrcmgr: Set PDFResourceManager object
arg2: device : Set TextConverter object
return: PDFPageInterpreter Object
PDFPageInterpreter object.process_page(page)
arg: page : Set PDFPage object
return: Output stream to console
These are the class specifications required to extract text from a PDF file. The following sections will introduce sample code that makes use of these classes (objects).
3. Text Extraction with Pdfminer.six

Up to this point, we have explained the classes required for text extraction. From here on, let’s follow the sample programs and check them concretely.
3.1 Output PDF text to Console
As the first sample code, try to read a PDF file, extract its contents (text only) and display them on the output console of Python (JupyterNotebook).<List1>
The PDF used in this program are available for download below.
The rough flow of the process is as follows.
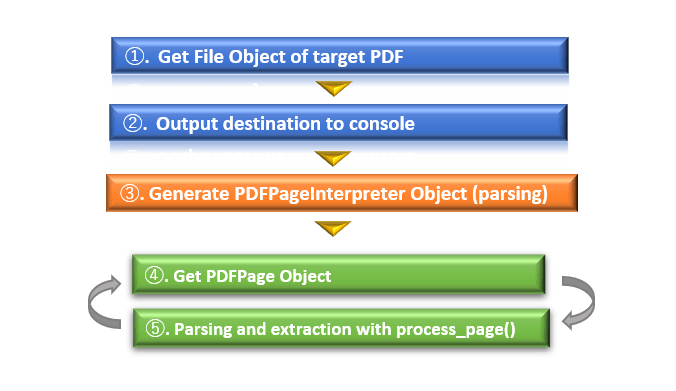
# Read PDF and output to Python console
# Import the required Pdfminer.six module(Class)
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.layout import LAParams
from io import StringIO
# Get File object with "binary mode" in built-in function open()
fp = open("pdfminer_sample1.pdf", 'rb')
# Get IO stream for output to Python console
outfp = StringIO()
# Obtaining objects required for text extraction
rmgr = PDFResourceManager() # Get PDFResourceManager object
lprms = LAParams() # Get LAParams object
device = TextConverter(rmgr, outfp, laparams=lprms) # Get TextConverter object
iprtr = PDFPageInterpreter(rmgr, device) # Get PDFPageInterpreter object
# Parsing (text extraction) one page at a time from PDF
for page in PDFPage.get_pages(fp):
iprtr.process_page(page)
text = outfp.getvalue() # Get Python console content
outfp.close() # Closing the I/O stream
device.close() # Releasing the TextConverter object
fp.close() # Closing the File stream
print(text) # Display in Jupyter's output boxLet me explain the key points.
Lines 4~9 import the necessary classes.
Get the File object of the PDF file to be read. The built-in Python function open() is specified to ‘rb‘ (read-only and binary mode). (Must be read in binary mode.)
Get a StringIO object to change the output destination from the console to the JupyterNotebook output window. The getvalue() method on line 29 will receive the result of the parsing.
By combining the objects of each class imported at the beginning of code, the PDFPageInterpreter object (for parsing and extracting text) is ultimately generated.
Pass it to the process_page() method of the PDFPageInterpreter object, analyze the contents, and extract the text.
Lines 31~33 also post-process the opened File object and I/O stream, then the TextConverter object, and terminate the program.
The result of executing <List1> is as follows

After reading the PDF file shown in Figure 5 left, all text in the file now appears in JupyterNotebook’s output window. It can be confirmed that the text is extracted faithfully without line breaks or garbled text as in the original.
If you wish to make changes to the layout of the text to be extracted, use <2.2 LAParams Object> to adjust accordingly.
3.2 Output PDF text to File
Now let’s also try an example of outputting PDF text to a Text file.
The only change is to change the output destination from an output stream (StringIO object) to a File file object. Specifically, simply replace line 15 of <List1> with the following line.
outfp = open("output.txt", 'w', encoding='utf-8')Note that the first argument of the standard function open() is the name of the destination file, and the mode setting of the second argument is ‘w‘(writing) or ‘a‘(appending). The third argument encoding type is ‘utf-8’.
Let’s replace line 15 of with the above and run it again.
Now, instead of window output, a text file named “output.txt” is output.
The contents of the file show that the text has been extracted without any problems. (Fig.6)

4.Get PDF Parsing Information

So far, we have introduced a class for extracting text in PDF and its code examples,however, PDF has many attributes and configuration information other than text. In this section, we would like to explain how to obtain and examine PDF parsing information.
Two more classes, the PDFParser class and the PDFDocument class are required to obtain parsing information. Each of them is responsible for “performing parsing” and “providing functions and attributes for handling PDF body information“. The specifications are as follows
from pdfminer.pdfparser import PDFParser
PDFParser(fp)
arg: fp: File object of the target PDF
return: PDFParser Object
from pdfminer.pdfdocument import PDFDocument
PDFDocument(parser)
arg: parser: Set parser information (PDFParser object)
return: PDFDocument Object
The PDFDocument object has many attributes and methods.
| PDFDocument Object.property | Functions | Others/Details |
|---|---|---|
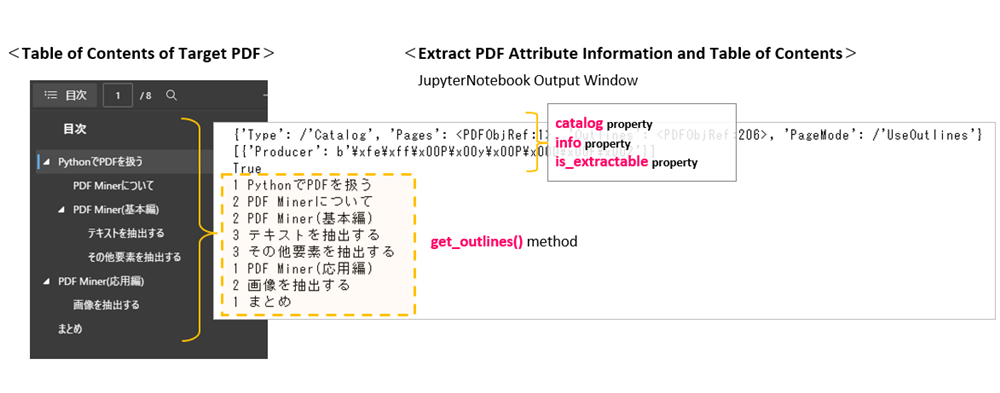
| catalog | Get a PDF configuration information | Ex {‘Type’: /’Catalog’, ‘Pages’: <PDFObjRef:1>, ‘Outlines’: <PDFObjRef:206>, ‘PageMode’: /’UseOutlines’} |
| encryption | PDF encryption settings (default: None) | |
| decippher | PDF decryption setting (default: None) | |
| info | Get PDF Attribute Information | ‘Author’、’CreationDate’、 ‘ModDate'(Update date)、’Producer'(Conversion Engine)、’Title'(Filename) |
| is_extractable | Get availability of content extraction | True(valid)/False(Invalid) |
| is_modifiable | Get edit availability | True(valid)/False(Invalid) |
| is_printable | Get print availability | True(Valid)/False(Invalid) |
| get_outlines() | Retrieve the table of contents |
Here is a sample code to parse a PDF file using “PDFParser class” and “PDFDocument class”.
The outline of the code is to check the various attributes in <Table4> and extract the table of contents (bookmarks) using the get_outlines() method.
# Program to parse PDF
# Import classes from Pdfminer.six module
# Class that provides functions and attributes for handling PDF body information
from pdfminer.pdfdocument import PDFDocument, PDFNoOutlines
# Class for performing parsing
from pdfminer.pdfparser import PDFParser
# ----------------------------------------------------------------------
# Get File object with "binary mode" in built-in function open()
fp = open("20210911224013.pdf", 'rb')
# Get PDFParser object
parser = PDFParser(fp)
# Get PDFDocument object
doc = PDFDocument(parser)
# ----------------------------------------------------------------------
# 【Check attributes of PDFDocument object】
# ➀Obtaining PDF configuration information
print(doc.catalog)
# >> {'Type': /'Catalog', 'Pages': <PDFObjRef:1>, 'Outlines': <PDFObjRef:206>, 'PageMode': /'UseOutlines'}
# ➁Obtaining PDF Attribute Information
print(doc.info)
# >> { 'Author': b'atsushi', 'CreationDate': b"D:20210321143519+09'00'",
# 'ModDate': b"D:20210321143519+09'00'", 'Producer': b'Microsoft: Print To PDF',
# 'Title': b'Microsoft Word - pdfminer_sample1.docx'}
# ➂Availability of content extraction
print(doc.is_extractable)
# >> True
# ----------------------------------------------------------------------
# 【Methods of PDFDocument object】
# Extracting text from the Table of Contents
try:
outlines = doc.get_outlines() # get_outlines() method returns Generater
for outline in outlines:
level = outline[0] # Get hierarchy of table of contents <index 0>
title = outline[1] # Get contents of table of contents <index 1>
print(level,title)
except PDFNoOutlines: # Error Handling for PDFs without Table of Contents
print("This content does not have a table of contents")Now, let me explain some key points.
Import the classes needed for parsing. The PDFNoOutlines class is used to catch errors when parsing files without a table of contents. If all you need is parsing, you only need PDFDocument, PDFParser class.
Generates the PDFParser object from a PDF file object to be parsed and retrieves the PDFDocument object.
The PDFDocument object provides attributes (properties) and methods to obtain syntax information of the PDF body.
The catalog property provides PDF structure information (page information, table of contents, PDFobjRef number, etc.). The info property provides PDF attribute information (author, creation date, conversion method). The is_extractable property allows you to check whether or not an extraction is possible.
Not only attributes but also methods are provided to extract the table of contents in the following.
The get_outlines() method can be used to extract the text of the PDF table of contents (bookmark). The generator is returned, so the individual elements are taken out at line 44. OutLine objects are in list format, with index “0” referring to the “hierarchy of the table of contents” and index “1” referring to the “text of the table of contents”.
Note that unlike the case of text extraction of the body text, it can be completed within the PDFDocument object, so there is no need to use the StringIO module to switch the output destination stream, as in <List1>.
Now let’s execute <List2>.
The PDF with the table of contents as shown in Fig. 7 left is read. The result is as shown in the right side of the same figure. You can see that the attribute information and the table of contents are extracted from the PDF.
5. Summary

How was it?
In this article, we have explained how to use the “PDFMiner.six” library to extract text information from PDF.
As mentioned at the beginning, PDF files have become the most common file format for today’s increasingly electronic management of documents.
“PDFMiner.six” and “Python” can be used together to automate content (text) extraction to enable batch processing of PDF-related tasks.
In addition, Python provides libraries that excel at analyzing various types of data, including machine learning. In addition to data statistics and visualization, new hints for data utilization may be discovered from big data obtained from a large volume of PDF.
We hope that the synergy between PDF and Python will make your work easier and more creative.
Now, let’s summarize the article content at the end.
➀. In addition to PDFMiner, there are libraries such as PyPDF2 and ReportLab that can manipulate PDF, and each has its own features and strengths and weaknesses.
PDFMiner is a library specialized in “extracting text”.
➁. PDFMiner supports Japanese, Chinese, and Korean, so it is a good match for Japanese.
➂. Just extracting text requires the combination of five different classes (objects), making for a complex structure. It is important to consider descriptions other than user-specific processing as routine processing.
This article is based on an article in the March 2020 issue of Nikkei Software, published by Nikkei Business Publications, Inc. We hope you will find this book useful in improving your skills.
We also explain “PyPDF2” as a library for manipulating PDF. Please refer to this as well.

Thank you for reading to the end.