
私たちが普段使っている利便性の高いファイル形式の一つに「PDF(Portable Document Format)」があります。
文章などのコンテンツをPDF化することで、
・元ファイルの容量を圧縮する
・元ファイルの内容を書き換えすることができないようする(保護)
・ReaderがインストールされたPCやスマホから簡単に閲覧・検索できる
などのようなことができるようになります。
今回はこのPDFファイルをPythonで操作する方法を紹介していきます。
PDFの「利便性と汎用性」と、Pythonの「拡張性、データ分析・処理など」それぞれの得意とする機能を掛け合わせることでさら活用の幅が広がることでしょう。

PythonからPDFファイルを操作するには専用の外部ライブラリをインストール・インポートする必要があります。
PDFを操作するライブラリには、PDFMiner, PyPDF2, ReportLab といったものなど、いくつか存在します。
ただし、PDFは非常に複雑な仕様となっているので一つのライブラリで全ての機能をカバーすることは現状ではできないようです。そのため、それぞれのライブラリには特徴や得意とする操作が異なります。ユーザーは目的に応じて使い分ける、もしくは組み合わせて使う必要があります。
そこで、目的や特徴によってどのように使い分けるかといった大まかな目安を次のようにまとめてみましたので参考にして下さい。

今回の記事ではこれらのうち「PDFMiner」を使って、PDFファイルからテキスト(文章)コンテンツを抽出する方法を図解で分かりやすく解説していきます。
また、開発環境は、パッケージ管理ソフト<Anaconda>が導入済みであることを前提としています。
記事内で動作確認した開発環境とバージョン情報は次のとおりとなります。異なる環境・バージョンのライブラリを使う際はこの点、ご留意ください。
1. PDFMinerの概要と導入

はじめに、PDFを操作するライブラリPDFMinerの概要を整理します。
PDFMinerは、テキストの抽出を得意としているようですが、その他のPDFを構成するコンテンツである画像(JPG,Bitmap)やテーブル(表)、しおりなどの抽出も可能です。
言語は「日本語」「中国語」「韓国語」をサポートし、縦書きの文章にも対応できるとのこと。また、Pythonの世代によって次のようにいくつかバージョンに別れています。
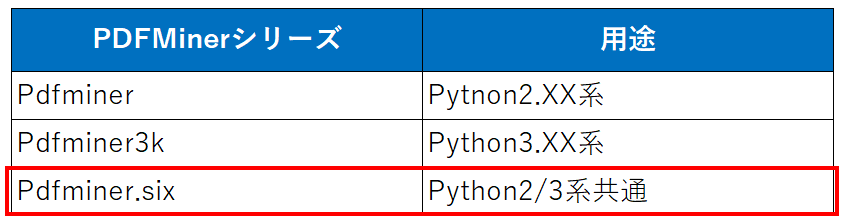
今回は、Python3.xであり、パッケージ管理コマンド pip を使ってお手軽にインストールすることができる「pdfminer.six」の使い方を解説してきます。
本サイトで紹介するクラスなどの使い方は一例です。省略可能なオプション引数などについては割愛していますので、詳細や不明点などは必要に応じて公式ドキュメントを適宜参照してください。
1.1 インストールと動作確認
pdfminer.six はAnacodaには同梱されていないのでpipなどを使って別途インストールする必要があります。Anacondaプロンプトに次のコマンドを入力しインストールしてください。
pip install pdfminer.six次に正常にインストールされたか確認してみましょう。
後述しますが、pdfminer.sixには多くのモジュールがあるのでどれか一つ選んで読込んでみます。例えば、pdfminer.pdfinterpモジュール から PDFResourceManagerクラス をインポート・実行して特にエラーメッセージ等が表示されなければ正常にイントールされています。
from pdfminer.pdfinterp import PDFResourceManager
rmgr = PDFResourceManager()2. テキスト抽出に必要なクラス

PDFのファイル仕様は複雑な構造となっているため「pdfminer.six」を使ってテキストを抽出するだけでも5つのクラスを利用する必要があります。まとめると、以下のようなクラスを必要とします。

各クラスから取得するオブジェクトどうしの相関系図は以下のようになります。(図2)
「PDFResorceManagerオブジェクト」は、PDF内のすべてのコンテンツ(テキスト・画像)を管理し、他のオブジェクトと連携し合います。最終的には、「PDFPageInterpreterオブジェクト」で構文解析とテキストの抽出を行うわけですが、図2のフローは、ある程度pdfminer.sixを使う上での決まり文句ということで覚えておくとよいでしょう。
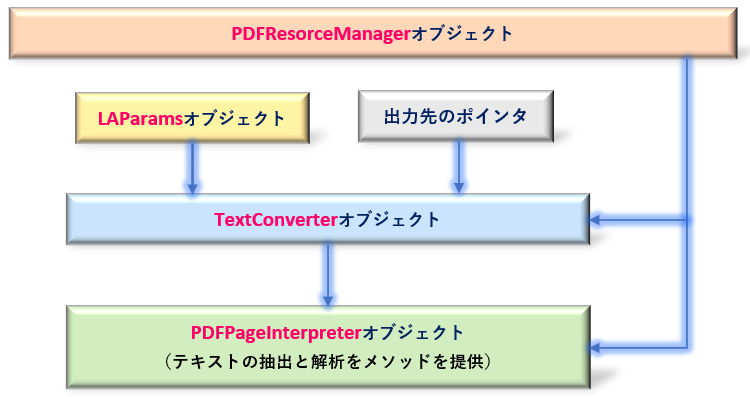
次項からは、各種オブジェクトを取得するためのクラスの仕様を解説します。
2.1 PDFResourceManagerオブジェクトの取得
「PDFResourceManagerクラス」は PDFファイル内のコンテンツ(テキストや画像など)やその他リソースを管理する基幹クラスとなります。
Pdfminer.sixにてPDFを操作するには、まずは「PDFResourceManagerオブジェクト」を取得することから始ります。
from pdfminer.pdfinterp import PDFResourceManager
PDFResourceManager()
戻り値: PDFResourceManagerオブジェクト
2.2 LAParamsオブジェクトの取得
「LAParamsクラス 」はテキスト抽出解析に必要なPDFファイルのレイアウト情報をパラメーターとして設定するするためのクラスとなります。
本記事では、全てデフォルト(引数指定なし)のままで解析するようにしています。縦文字や図形内のテキストも抽出したい場合などは、適切に設定するようにします。詳細は、公式サイトを参照してください。
from pdfminer.layout import LAParams
LAParams(line_overlap, char_margin, detect_vertical, all_texts)
引数: line_overlap: 途中改行が必要な単語の分割可否を判断する閾値(デフォルト:0.5)
引数: char_margin: 単語間の間隔(デフォルト:2.0)
引数: detect_vertical: 縦文字の解析を許可するか(デフォルト:False)
引数: all_texts: 図形内のテキストも解析の対象とするか(デフォルト:False)
戻り値: LAParamsオブジェクト
ほか省略可能な引数は多数,全てオプショナル引数
2.3 TextConverterオブジェクトの取得
「TextConverterクラス」はPDFファイル内のテキストを抽出する機能を提供するクラスとなります。
引数:rsrcmgr には<2.1 PDFResourceManagerオブジェクト>を、引数:laparams には<2.2 LAParamsオブジェクト>を設定します。pdfminerで解析・抽出したテキストの出力先はPythonコンソール、もしくはファイルとなります。引数:outfp には出力先のストリームを渡します。
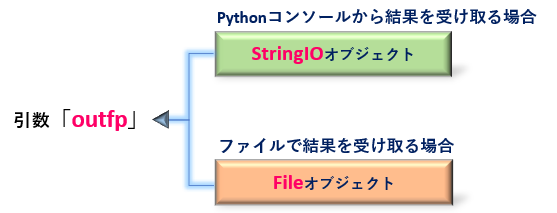
from pdfminer.converter import TextConverter
TextConverter(rsrcmgr, outfp, laparams)
引数1: rsrcmgr: PDFResourceManagerオブジェクトを設定する
引数2: outfp: 出力先のストリームオブジェクトを設定する
引数3: laparams: LAParamsオブジェクトを設定する
戻り値: TextConverterオブジェクト
2.4 PDFPageオブジェクトの取得
「PDFPageクラス」は ファイルからページ毎の個別情報を取得するジェネレーターを生成します。
通常はさらに、get_pages()メソッド、create_pages()メソッド を繋げて、PDFPageオブジェクト を取得することになります。
但し、この2つのメソッドに渡す、オブジェクトは異なります。前者は解析対象となるPDFを指し示すファイルオブジェクトを、後者は PDFDcumentオブジェクト (後述します)を引数に渡すことになります。
from pdfminer.pdfpage import PDFPage
PDFPage.get_pages(fp, password)
引数1: fp :解析対象のPDFのファイルポインタを設定
引数2: password :パスワードを設定(省略可能) 文字列で指定する
戻り値: PDFPageオブジェクト
PDFPage.create_pages(doc)
引数: doc :PDFDocumentオブジェクトを指定する
戻り値: PDFPageオブジェクト
2.5 PDFPageInterpreterオブジェクトの取得
「PDFPageInterpreterクラス」は取得したPDFPageオブジェクトを解析する機能を提供します。
引数:rsrcmgr には<2.1 PDFResourceManagerオブジェクト>を、引数:device には
<2.3 TextConverterオブジェクト>を設定します。
from pdfminer.pdfinterp import PDFPageInterpreter
PDFPageInterpreter(rsrcmgr, device)
引数1: rsrcmgr :PDFResourceManagerオブジェクトを設定
引数2: device :TextConverterオブジェクトを設定
戻り値: PDFPageInterpreterオブジェクト
PDFPageInterpreterオブジェクト.process_page(page)
引数: page :PDFPageオブジェクトを設定
戻り値: コンソールへの出力ストリーム
以上が、PDFファイルからテキストを抽出するのに必要となるクラスの仕様でした。以降は、実際にこれらのクラス(オブジェクト)を活用するサンプルコードを紹介していきます。
3. pdfminer.sixによるテキスト抽出

テキスト抽出に必要なクラスが分かったところで、ここからは具体的なサンプルプログラムを追いながら確認していきましょう。
3.1 PDFのテキストをコンソールに出力する
1つ目のサンプルコードとして、PDFファイルを読込んでコンテンツ内容(テキストのみ)を抜き出してPython(JupyterNotebook)の出力ウィンドウに表示してみましょう。<List1>
このプログラムで使用したPDFファイルは以下からダウンロード可能できます。
大まかな処理の流れは以下の通りとなります。
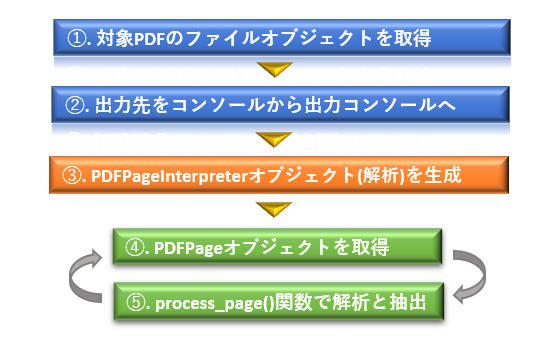
# PDFファイルを読込んで、Pythonのコンソールに出力する
# 必要なPdfminer.sixモジュールのクラスをインポート
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.converter import TextConverter
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.layout import LAParams
from io import StringIO
# 標準組込み関数open()でモード指定をbinaryでFileオブジェクトを取得
fp = open("pdfminer_sample1.pdf", 'rb')
# 出力先をPythonコンソールするためにIOストリームを取得
outfp = StringIO()
# 各種テキスト抽出に必要なPdfminer.sixのオブジェクトを取得する処理
rmgr = PDFResourceManager() # PDFResourceManagerオブジェクトの取得
lprms = LAParams() # LAParamsオブジェクトの取得
device = TextConverter(rmgr, outfp, laparams=lprms) # TextConverterオブジェクトの取得
iprtr = PDFPageInterpreter(rmgr, device) # PDFPageInterpreterオブジェクトの取得
# PDFファイルから1ページずつ解析(テキスト抽出)処理する
for page in PDFPage.get_pages(fp):
iprtr.process_page(page)
text = outfp.getvalue() # Pythonコンソールへの出力内容を取得
outfp.close() # I/Oストリームを閉じる
device.close() # TextConverterオブジェクトの解放
fp.close() # Fileストリームを閉じる
print(text) # Jupyterの出力ボックスに表示するそれでは、ポイントを解説します。
4~9行目で必要なクラスをインポートしています。
読み込むPDFファイルをPythonの組込み 関数open() のモードを’rb’(読取専用かつバイナリモード)に指定してFileオブジェクトを取得します。(必ずバイナリモードで読み込む必要があります。)
出力先をコンソールからJupyterNotebookの出力ウィンドウに変更するために、StringIOオブジェクトを取得します。29行目の getvalue()メソッド で解析結果を受け取ることになります。
冒頭でインポートした各クラスのオブジェクトを組合わせることで最終的に PDFPageInterpreterオブジェクト (テキストの解析・抽出する)を生成しています。
PDFから個別ページ情報のPDFPageオブジェクトを取得し、PDFPageInterpreterオブジェクトの process_page()メソッド でコンテンツを解析、テキスト抽出を実行します。
また、31~33行目は開いたFileオブジェクトとI/Oストリーム、それからTextConverterオブジェクトの後処理をしてプログラムを終了します。
<List1>を実行した結果は次のようになりました。
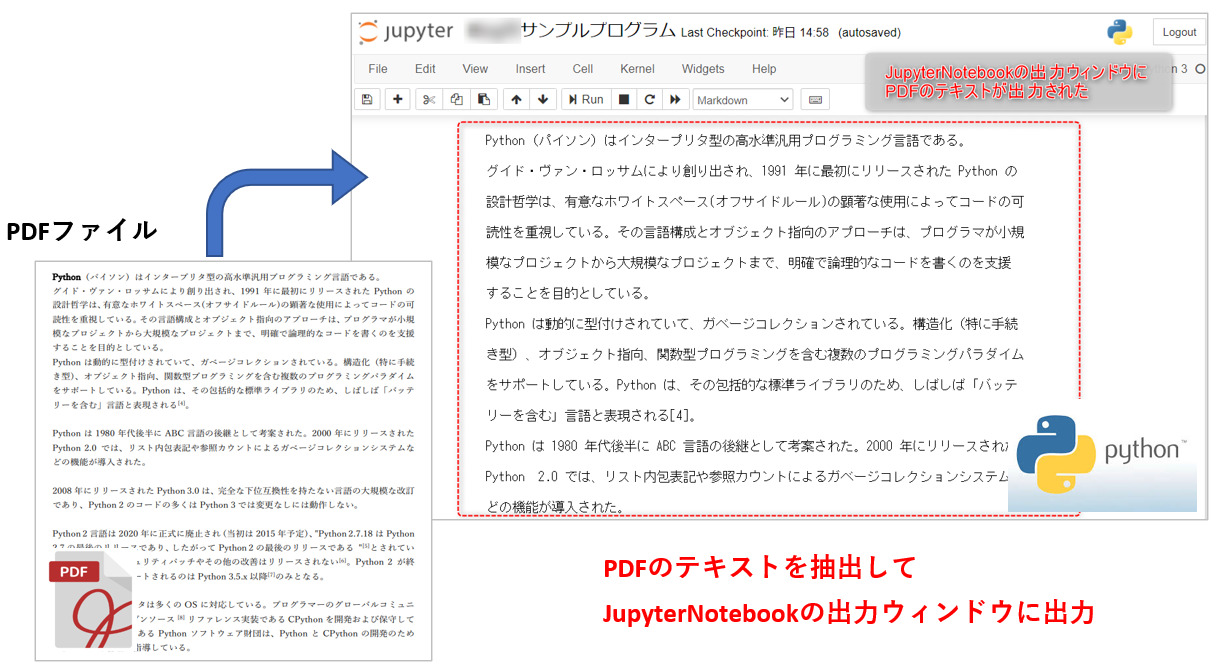
図5左のPDFファイルを読込んで、ファイル内の全てのテキストがJupyterNotebookの出力ウィンドウに表示されました。原文のとおり改行されや文字化けもなく忠実に抽出できていることが確認できます。
もし、抽出するテキストのレイアウトに変更を加えたい場合は、<2.2 LAParamsオブジェクト>で適宜調整するようにします。
3.2 PDFのテキストをファイルに出力する
今度はPDFのテキストをTextファイルに出力する例も試してみましょう。
変更点は、出力先を出力ストリーム(StringIOオブジェクト)からFileファイルオブジェクトにするだけとなります。具体的には<List1>の15行目を次の1行に差し替えるだけで対応できます。
outfp = open("output.txt", 'w', encoding='utf-8')標準関数open() の第1引数に出力先のファイル名を、第2引数のモード設定は ‘w’書き込み もしくは ’a’追記指定 する点に注意してください。第3引数encodingタイプは ‘utf-8’とします。
<List1>の15行目を上記と差し替えて再度実行してみましょう。
今度は、ウィンドウではなく、“output.txt”というテキストファイルが出力されました。
中身を確認すると先ほどと同様、問題なくテキストが抽出されていることが分かります。(図6)

4. PDFの構文解析情報を取得する

さてここまでは、PDF内のテキストを抽出するクラスとそのコード例を紹介してきましたが、PDFにはテキスト以外にも多くの属性や構成情報を保有しています。本節では、PDFの構文解析情報を取得して調べる方法について解説したいと思います。
構文解析情報を得るには、さらに「PDFParserクラス」と「PDFDocumentクラス」という2つのクラスが必要になります。それぞれ、「構文解析を実行する」「PDF本体情報を扱うための機能や属性を提供する」という役割があり、仕様は次の通りとなります。
from pdfminer.pdfparser import PDFParser
PDFParser(fp)
引数: fp: 処理対象PDFのファイルオブジェクト
戻り値: PDFParserオブジェクト
from pdfminer.pdfdocument import PDFDocument
PDFDocument(parser)
引数: parser: 構文解析情報(PDFParserオブジェクト)を設定する
戻り値: PDFDocumentオブジェクト
PDFDocumentオブジェクトには、多くの属性やメソッドが用意されています。
| PDFDocumentオブジェクト.プロパティ | 機能 | その他・詳細 |
|---|---|---|
| catalog | PDFの構成情報の取得 | 例 {‘Type’: /’Catalog’, ‘Pages’: <PDFObjRef:1>, ‘Outlines’: <PDFObjRef:206>, ‘PageMode’: /’UseOutlines’} |
| encryption | PDFの暗号化の設定(デフォルト:None) | |
| decippher | PDFの暗号の解除設定(デフォルト:None) | |
| info | PDFの属性情報の取得 | ‘Author'(編集者)、’CreationDate'(作成日)、 ‘ModDate'(更新日)、’Producer'(変換エンジン)、’Title'(ファイル名) |
| is_extractable | コンテンツ抽出の可否の取得 | True(可能)/False(不可) |
| is_modifiable | 編集の可否の取得 | True(可能)/False(不可) |
| is_printable | 印刷の可否の取得 | True(可能)/False(不可) |
| get_outlines() | 目次を取得する |
それでは「PDFParserクラス」と「PDFDocumentクラス」を活用してPDFファイルの構文解析をおこなうサンプルコードを紹介します。
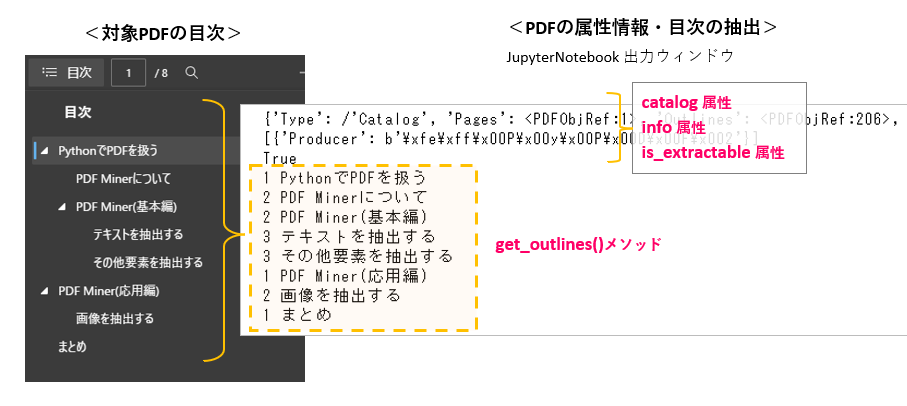
コードの概要は、<表4>の各種属性の確認と get_outlines()メソッド による目次(しおり)の抽出となります。
# PDFファイルの構文解析を行うプログラム
# Pdfminer.sixモジュールのクラスをインポート
# PDF本体情報を扱うための機能や属性を提供するクラス
from pdfminer.pdfdocument import PDFDocument, PDFNoOutlines
# 構文解析を実行するクラス
from pdfminer.pdfparser import PDFParser
# ----------------------------------------------------------------------
# 標準組込み関数open()で解析対象PDFのFileオブジェクトを"Binary"モードで取得
fp = open("20210911224013.pdf", 'rb')
# PDFParserオブジェクトの取得
parser = PDFParser(fp)
# PDFDocumentオブジェクトの取得
doc = PDFDocument(parser)
# ----------------------------------------------------------------------
# 【PDFDocumentオブジェクトの属性確認】
# ➀PDFの構成情報の取得
print(doc.catalog)
# >> {'Type': /'Catalog', 'Pages': <PDFObjRef:1>, 'Outlines': <PDFObjRef:206>, 'PageMode': /'UseOutlines'}
# ➁PDFの属性情報の取得
print(doc.info)
# >> { 'Author': b'atsushi', 'CreationDate': b"D:20210321143519+09'00'",
# 'ModDate': b"D:20210321143519+09'00'", 'Producer': b'Microsoft: Print To PDF',
# 'Title': b'Microsoft Word - pdfminer_sample1.docx'}
# ➂コンテンツ抽出の可否
print(doc.is_extractable)
# >> True
# ----------------------------------------------------------------------
# 【PDFDocumentオブジェクトのメソッド】
# <目次>のテキストを抽出する
try:
outlines = doc.get_outlines() # get_outlines()メソッドはGeneraterを戻す
for outline in outlines:
level = outline[0] # 目次の階層を取得 <インデックス0>
title = outline[1] # 目次のコンテンツを取得 <インデックス1>
print(level,title)
except PDFNoOutlines: # 目次がないPDFの場合のエラー処理対策
print("このコンテンツには目次はありません")それでは、ポイントを解説します。
構文解析に必要なクラスをインポートします。PDFNoOutlinesクラス は目次がないファイルを解析した場合にエラーを捕捉するために使います。構文解析をするだけなら、PDFDocument, PDFParserクラスだけで済みます
解析対象のPDFのファイルオブジェクトから、PDFParserオブジェクト を生成、さらに PDFDocumentオブジェクト を取得します。
PDFDocumentオブジェクトは、PDF本体の構文情報を得るための属性(プロパティ)やメソッドを提供しています。
catalog属性 では、PDFの構成情報(ページ情報、目次、PDFobjRef番号)などが得られます。また、info属性 では、PDFの属性情報(作成者、作成日、変換方法)が得られます。is_extractable属性 では、抽出の可否を調べることができます。
属性だけではなくメソッドも提供されており、次では目次を抽出します。
get_outlines()メソッド を使うことで、PDFの目次(しおり)のテキストを抽出できます。ジェネレータを戻すので、44行目で個別要素を取り出します。OutLineオブジェクトはリスト形式であり、インデックス「0」で「目次の階層」を、インデックス「1」で「目次のテキスト」を参照できます。
なお、本文のテキスト抽出の場合とは異なりPDFDocumentオブジェクト内で完結できるため、<List1>のように、StringIOモジュールを使って出力先のストリームの切替えは必要はありません。
それでは、実際に<List2>のコードを実行してみましょう。
図7左のような目次をもった、解析対象となるPDFを読込んだけ結果が、図7右のようになります。PDFの属性情報や目次のテキスト抽出がおこなわれていることが確認できます。
5. まとめ

いかがでしたでしょうか?
今回はPDFからテキスト情報を抽出する「PDFMiner.six」ライブラリの使い方について解説してきました。
冒頭でも述べたようにPDFファイルはドキュメントの電子化管理が進む現代にとって最も一般的なファイル形式となっています。
「PDFMiner.six」とPythonを組合わせてコンテンツ(テキスト)の抽出を自動化できれば、PDFに関連した作業を一括処理できるようになります。
さらに、Pythonには、機械学習をはじめとした様々なデータ分析を得意とするライブラリが提供されています。データの統計・可視化は勿論のこと、大量のPDFから取得したビッグデータから新たなデータ活用のヒントが発見できる可能性もあります。
PDFとPythonの相乗効果で貴方の仕事をもっと「楽に」「クリエイティブなもの」にして頂けることを願っています。
では、ここで今回の記事内容をまとめておきましょう。
➀. PDFを操作することができるライブラリには「PDFMiner」の他「PyPDF2」「ReportLab」といったものがあり、それぞれ特徴と得意・不得意なことがある。今回紹介したPDFMinerは「テキストを抽出する」ことに特化したライブラリ。
➁. PDFMinerに対応する言語は英語以外にも「日本語」「中国語」「韓国語」に対応しているため、日本人にとっては相性の良い。
➂.テキストを抽出するだけでも5種類のクラス(オブジェクト)を組合わせる必要があり複雑な構造をとる。ある程度、定型処理として割り切り、ユーザー固有処理の記述に専念するのが肝要と考える。
また、本記事は日経BP社「日経ソフトウェア」さんの2020年3月号の一部記事を参考にした上で、筆者独自の視点による解説を加えています。ぜひ、こちらの書籍も参考にスキル向上にお役立てください。
PDFを操るライブラリとして、「PyPDF2」も解説しています。ぜひ、こちらも参考になさってください。

最後までお読みいただきありがとうございました。