
シリーズ「Pythonプログラミングの始め方」ではPythonの基礎文法を図を用いて分かりやすく解説していきます。
今回はPythonのデータ構造の一つであるリスト<list>に関連する基本的な操作方法について解説していきます。
重要度:★★★★★
- リストの生成・参照と更新について
- 多次元リストについて
- リストの連結と比較
その他、リストオブジェクトの応用編として、オブジェクト配下のメソッドの解説もこちらの記事で行っておりますので、参照してください。

Pythonでは、主にリストを使ってデータの処理を行っていくという特徴があります。また、他のプログラミング言語でいうところの「配列」に相当するものですが、通常の配列とリストでは、次のような点で違いがあります、理解しておきましょう。
- 要素数の可変長がしやすい。
- 異なるデータ型の要素を混在させることができる
- 物理メモリ配置(アドレス)を意識しない
また、Python公式ドキュメントのリストに関する定義は以下になりますので必要に応じて参照してください。
Python公式ドキュメントの引用
https://docs.python.org/ja/3/library/stdtypes.html#list
それでは、次節よりリストを生成する方法から、解説をしていきます。
1. リストを生成する

リストを生成する方法について、解説していきます。[,](カッコ)の中に、要素を記述していく基本スタイル<1.1項>の他に、組込み関数を用いる生成方法<1.2項>もあります。
1.1 []を使ってリストを定義する
リストをつくる方法はいくつかあるのですが、もっとも基本となるのが、”[”, “]” の中に要素(整数や文字列)をカンマ区切りで設定していく方法です。
まずは、基本ルール(書式)について整理したあとに、具体例をサンプルコードで確認してみます。
リストの書式 (1)
各要素には、整数、実数、文字列、ブール値、タプルなどのイミュータブルな要素、さらには、リストや辞書といったミュータブルなものをもたせることができます。(図1)

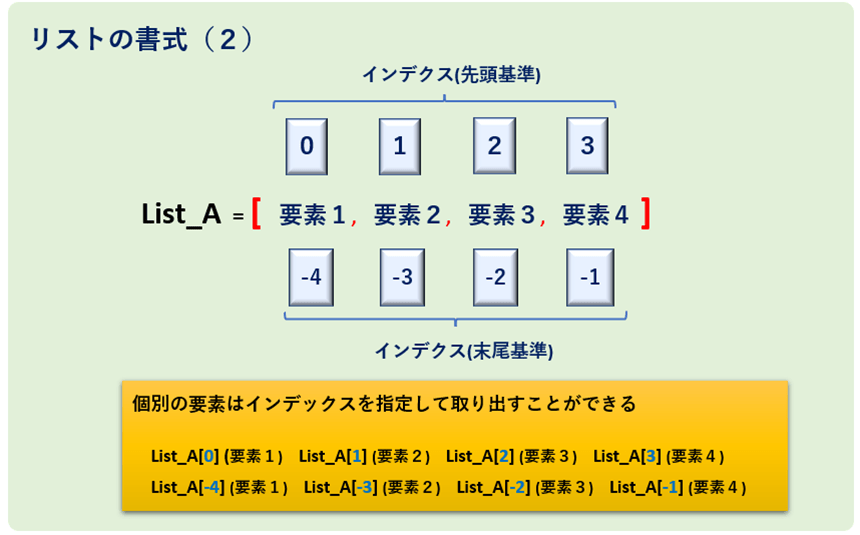
リストの書式 (2)
また、リストを構成する各要素には、以下図2のように「インデックス」という識別番号が割り振られています。例えば図2のようにList_Aとラベル付けされたリストがあった場合には、List_A[0], List_A[1]…, List_A[-1], List_A[-2]といったように、個別に各要素にアクセス(参照・更新)することができます。
リストの更新・参照については別途解説します。
リストの書式 (3)
その他、リストの生成の基本ルールとしては次のようなものがあります。
以上がリストの生成(定義)方法となります、それでは、具体例をサンプルコードで確認してみましょう。
例1. もっとも基本的なリストの作成例となります。リストの要素には整数や文字列、あるいはそれらを混在させることができます。また、文字列は “” , ‘’ のどちらを使っても定義できますが、定義後は自動的に ‘’ (シングルクォート) に統一されます。
# []を使ったリスト作成の基本
# 要素が整数の場合
numbers = [4, 8, 15, 16, 23, 42]
print(numbers)
# ➀>> [4, 8, 15, 16, 23, 42]
# 要素が文字列の場合
colors = ["red", "green", 'blue']
print(colors)
# ➁>> ['red', 'green', 'blue']
# 要素が整数と文字列、ブール値の混在
mixture = [1, 2, 3, "a", "b", "c", True, False]
print(mixture)
# ➂>> [1, 2, 3, 'a', 'b', 'c', True, False]➀》[4, 8, 15, 16, 23, 42]
➁》[‘red’, ‘green’, ‘blue’]
要素に整数と文字列、ブール値を混在させる
➂》[1, 2, 3, ‘a’, ‘b’, ‘c’, True, False]
例2. 値を割り当てた変数を、リストの要素にすることができます。生成したリストオブジェクトでは、変数が指す値が要素に置き変わります。(変数名がそのまま要素になるわけではないので注意してください。
a = 10 # 変数を初期化する
b = 20
c = 30
d = 'ABC'
e = True
#----------------------------------------------------------------------
# 変数を要素に指定してリストを定義する
result = [a, b, c, d, e]
print(result)
# ➃>> [10, 20, 30, 'ABC', True] 変数の値を要素とするリストが作成される要素に変数を設定して定義する
➃》[10, 20, 30, ‘ABC’, True]
例3. リストの要素には、例1の整数や文字列といったイミュータブルな要素の他にも、リストや辞書といったミュータブルな要素も置くことができます。これらはもちろん同じリスト(オブジェクト)内で混在できます。
list_obj = [1, 2, 4]
dict_obj = {"key1": 1, "key2" : 2}
tuple_obj = ('a', 'b', 'c')
#----------------------------------------------------------------------
# リスト, 辞書(ミュータブル), タプル(イミュータブル)を要素にする
print([list_obj, dict_obj, tuple_obj])
# ➄>> [[1, 2, 4], {'key1': 1, 'key2': 2}, ('a', 'b', 'c')]ミュータブルやイミュータブルなオブジェクトの混在
➄》[[1, 2, 4], {‘key1’: 1, ‘key2’: 2}, (‘a’, ‘b’, ‘c’)]
1.2 組込み関数「list()」でリストを定義する
リストを生成するもう一つの方法が、組込み関数 list() を用いるものです。引数に「文字列」や「タプル」や「辞書」「Rangeオブジェクト」といった イテラブルなオブジェクト を指定してそれらを要素としたあらたなリストを生成することができます。書式は次の通りです。
list(iterable)
引数1: iterable :イテラブルなオブジェクトを指定する
イテラブルなオブジェクトにはrangeオブジェクト, タプル, 文字列がある
引数を省略した場合は、空のリストが生成される
戻り値: Listオブジェクト
それでは、組込み関数list()の活用例をサンプルコードで確認してみましょう。
以下の4点の動作確認をしています。
(a) Rangeオブジェクトを引数指定する(始点、終点、ステップで指定できる)
(b) タプルや辞書を引数に指定する(辞書は、キーが要素の対象となる)
(c) 文字列を引数に指定する(各文字に分解されて要素となる)
(d) 引数指定なしの場合は空のリストが生成される
# list関数の引数にイテラブルなオブジェクトを使ったリストの作成例
# 引数にrangeオブジェクト(始点,終点)を指定
list_range = list(range(-2, 2))
print(list_range)
# ➀>> [-2, -1, 0, 1]
# 引数にrangeオブジェクト(始点,終点,ステップ)を指定
list_even = list(range(0, 10, 2))
print(list_even)
# ➁>> [0, 2, 4, 6, 8]
# 引数にrangeオブジェクトを指定し3の倍数をもつリストを生成
list_x3 = list(range(0, 15, 3))
print(list_x3)
# ➂>> [0, 3, 6, 9, 12]
#-----------------------------------------------------------------------------------------------
# list関数の引数にその他イテラブルなオブジェクトを使ったリストの作成
# 引数にタプルを指定
list_tuple = list((1,2,3,4))
print(list_tuple)
# ➃>> [1, 2, 3, 4]
# 引数に辞書を指定(keyのみ要素となることに注意)
list_dict = list({'key1':1, 'key2':2})
print(list_dict)
# ➄>> ['key1', 'key2']list()関数の引数にRangeオブジェクトを指定
➀》[-2, -1, 0, 1]
➁》[0, 2, 4, 6, 8]
➂》[0, 3, 6, 9, 12]
list()関数の引数にタプルや辞書を指定
➃》[1, 2, 3, 4]
➄》[‘key1’, ‘key2’]
# list関数の引数に文字列を指定したリストの作成例
list_words = list("日月火水木金土")
print(list_words)
# >> ['日', '月', '火', '水', '木', '金', '土']
list_words = list("Hello World")
print(list_words)
# >> ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
#-----------------------------------------------------------------------------------------------
# list関数の引数を省略した場合
list_brank = list() #引数なし
print(list_brank)
# >> []以上が、リストを生成する方法の解説となります。次節は要素の「参照」と「更新」をする方法についてです。
2. リストの要素の参照と更新
<1.1項>でも触れましたが、リストを構成する各要素には、「インデックス」という識別子が割り振られています。インデックスを指定して各要素へアクセスします。
つまり、要素を参照したり、更新することができます。
本節では、リストの参照と更新する方法として、まずは「単純(1次元)リスト」について触れたのち、「多次元リスト」について解説します。他言語の「配列」のようにPythonのリストには、多重のインデックスを振ることでマトリックス状のデータ構造を持たせることができます。<2.1, 2.2項>
そして、Pythonには、独自のアクセス方式として「スライス」という参照方法があります。<2.3項>
2.1 単純(1次元)リストの参照と更新
単純(1次元)リスト、いわゆる通常のリスト構造となります。先述のとり、各要素には、「インデックス」という識別子が割り振られています。インデックスを指定して各要素へアクセスします。
インデックスは図3のように「前方から基準をとる場合」と「後方からとる場合」の2通りの方法で指定できます。
どちらの指定方法でも構いませんが、前方から指定する場合はインデックスは先頭の要素を「0」とし以降昇順に割り振れています。一方、末尾を基準とする場合は、末尾を「-1」として先頭の要素に向かって[-2][-3]・・・降順に続きます。
要素の参照は、上記のようにリストオブジェクトにインデックスを指定することで戻り値として得ることができます。
更新は、代入演算子「=」を用いて直接、要素を上書きすることで対応できます。
リストは「ミュータブル」なオブジェクトなので、既存の要素を自由に更新・追加・削除ができます。(削除については、remove/popメソッドなどを使用します。オブジェクトのメソッドについては別記事で解説します。)
<単純リスト(1次元)の参照>
リスト名[index]
引数: index: 要素の参照位置、基準の取り方によって前方指定、後方指定2通りのある。
- 先頭基準:要素の先頭から0、1、2、3、4・・・
- 末尾基準:要素の末尾から-1、-2、-3、-4、-5・・・
<単純リスト(1次元)の更新>
リスト名[index]= ミュータブル/イミュータブルな値(オブジェクト)
引数: index: 更新する対象の要素のインデックスを指定する。
指定方法は、<参照>の時と同様に先頭基準と末尾基準で指定できる。
それでは、サンプルコードで確認してみましょう。
まずは、要素への参照する例です。前方からと後方からのそれぞれについて確認しています。<List6>
# 単純(一次)リストの参照と更新
#--------------------------------------------------------------------
# インデックスをつかったリストの参照
words = ["blue", "red", "green", "yellow"] # 元のリスト
#インデックスを前方基準で参照する場合
print(words[0]) # >>blue 先頭の要素のインデックスを「0」とする
print(words[1]) # >>red
print(words[2]) # >>green
print(words[3]) # >>yellow
#インデックスを後方基準で参照する場合
print(words[-1]) # >>yellow 末尾の要素のインデックスを「-1」とする
print(words[-2]) # >>green
print(words[-3]) # >>red
print(words[-4]) # >>blue
print(words) # >>['blue', 'red', 'green', 'yellow'] 元のリストは維持される次に、要素の更新する例です。<List7>
# インデックスをつかったリストの更新
# 先頭要素を「1234」に切り替える
words[0] = 1234
print(words) # ➀>> [1234, 'red', 'green', 'yellow']
# 末尾の要素を「4321」に切り替える
words[-1] = 4321
print(words) # ➁>> [1234, 'red', 'green', 4321]先頭要素を更新する
➀》[1234, ‘red’, ‘green’, ‘yellow’]
末尾の要素を更新する
➁》[1234, ‘red’, ‘green’, 4321]
2.2 多重リストの参照と更新
リストの要素にさらにリストを設定する、つまりリストのネスト構造(2次元)にすることもできます。(図4)2次元リストの書式は、以下のようになります。
外側の要素(親要素)と各要素となるリストの子要素がそれぞれ個別にインデックス指定することでアクセス(参照と更新)ができます。
順番は、「親→子」要素の順でインデックスを指定します。また、1次元リストと同様に基準を先頭・末尾で自由に指定できます。(そろえても、混載させても構いません)
<多重(2次元)リストの参照>
リスト名[index1][index2]
引数: index1: 外側(親要素)のインデックス
引数: index2: 内側(子要素)のインデックス ※親要素の参照時は省略する
戻り値: 指定した番地の要素
各インデックスは、先頭・末尾基準が可能 (単純リストと同様)
<多重(2次元)リストの更新>
リスト名[index1][index2] = ミュータブル/イミュータブルな値(オブジェクト)
引数: index1/index2: 更新する対象の要素のインデックス
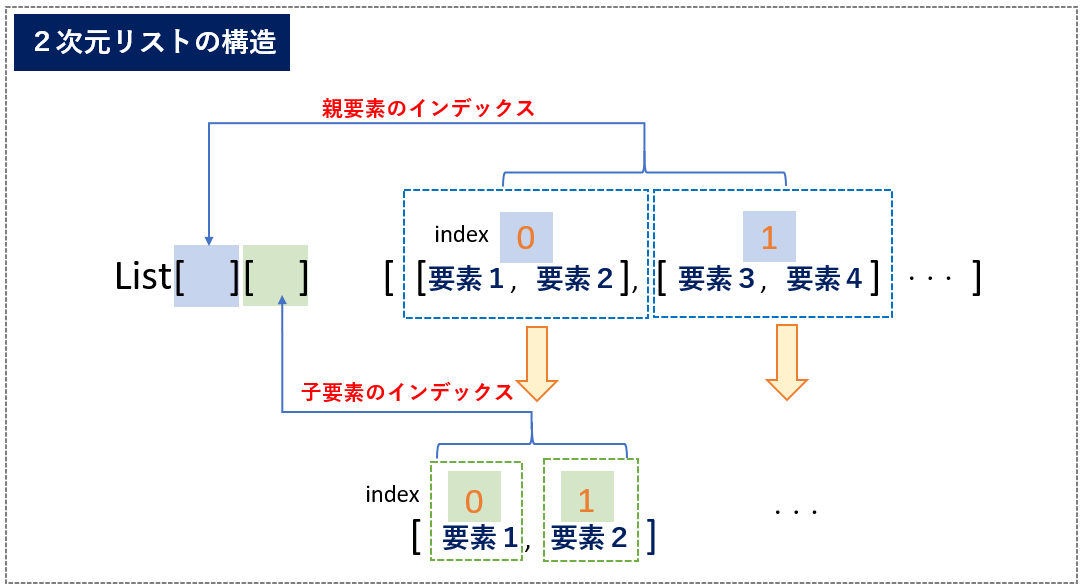
2次元リストも同様に、参照と更新ができます。以下の実行例<List8>では、要素を参照しています。親要素と子要素にそれぞれアクセスしています。
親要素の参照は、リスト名[index1]でインデックスを指定し、子要素は、リスト名[index1] [index2]のようにインデックス指定します。
# 多重リスト(2次元)の参照と更新
#--------------------------------------------------------------------
# 元のリスト
list_a = [["apple", "peach", "orange"], ["cabbage", "carrot", "potato"]]
print(list_a) # >>[['apple', 'peach', 'orange'], ['cabbage', 'carrot', 'potato']]
#---------------------------------------------------------------------
# 親要素の参照
print(list_a[0]) # >>['apple', 'peach', 'orange']
print(list_a[1]) # >>['cabbage', 'carrot', 'potato']
#---------------------------------------------------------------------
# 子要素の参照
# 親要素インデックス「0」の子要素の参照
print(list_a[0][0]) # >> apple
print(list_a[0][1]) # >> peach
print(list_a[0][2]) # >> orange
# 親要素インデックス「1」の子要素の参照
print(list_a[1][0]) # >> cabbage
print(list_a[1][1]) # >> carrot
print(list_a[1][2]) # >> potato更新の場合も同様に、各次数の要素にアクセスして上書きしています。<List9>
# 親要素の更新--------------------------------
# 親要素のインデックス「0」を更新
list_a[0] = [123, 456]
print(list_a) # ➀>>[[123, 456], ['cabbage', 'carrot', 'potato']]
# 子要素の更新--------------------------------
# 親要素のインデックス「1」、子要素のインデックス「1」を更新
list_a[1][1] = 456
print(list_a) # ➁>>[[123, 456], ['cabbage', 456, 'potato']]親要素の更新
➀》[[123, 456], [‘cabbage’, ‘carrot’, ‘potato’]]
子要素の更新
➁》[[123, 456], [‘cabbage’, 456, ‘potato’]]
さらに、要素をネストさせて以下のように3次元リストも定義することもできます。仕様上は、生成できるリストの次数に上限はないのでさらに階層を深くすることができますが、次数を増やすごとに構造が複雑となり可読性の低下やバグの温床になるので3次よりも深いリスト構造はあまり使用されません。
<多重(3次元)リストの参照>
リスト名[index1][index2][index3]
引数: index1: 外側(親要素)のインデックス
引数: index2: 内側(子要素)のインデックス ※親要素の参照時は省略する
引数: index3: 内々側(孫要素)のインデックス ※親又は子要素の参照時は省略する
戻り値: 指定した番地の要素
各インデックスは、先頭・末尾基準が可能 (単純リストと同様)
<多重(3次元)リストの更新>
リスト名[index1][index2][index3] = ミュータブル/イミュータブルな値(オブジェクト)
引数: index1/index2/index3: 更新する対象の要素のインデックス
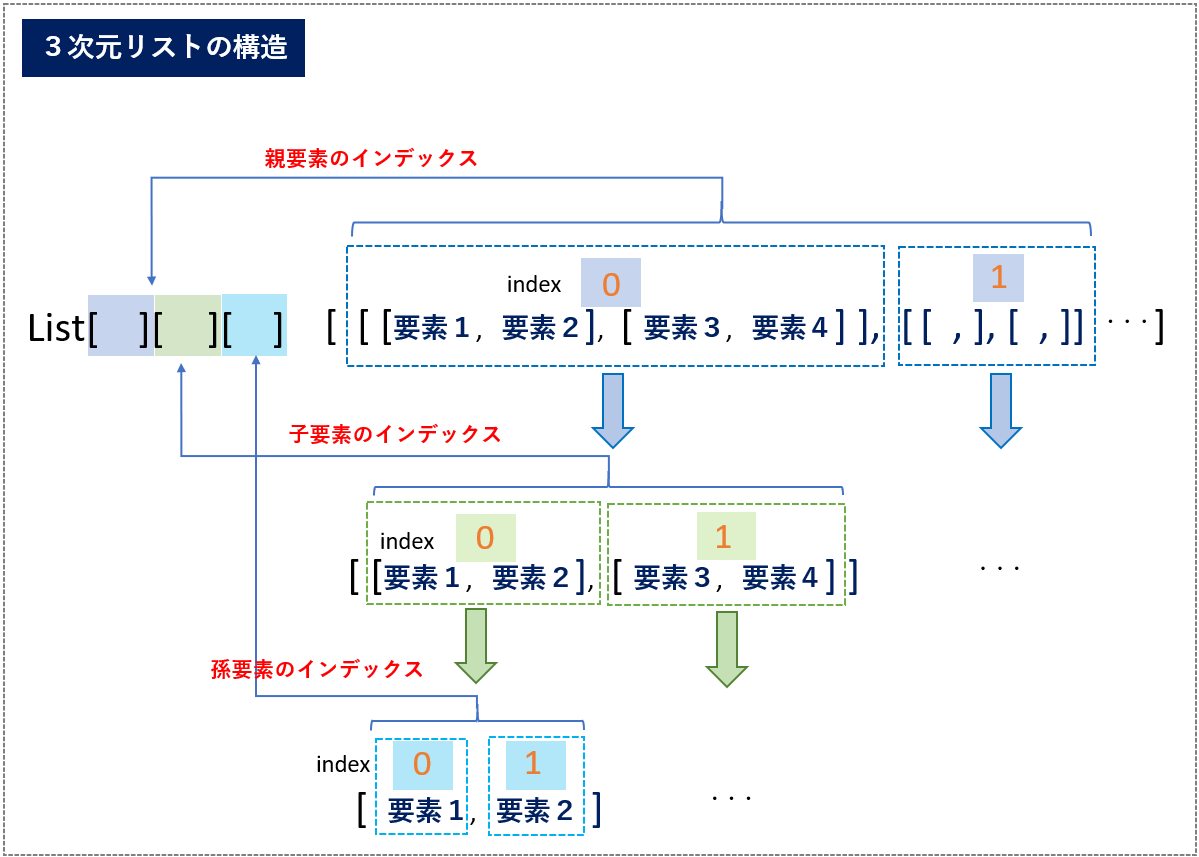
3次以降のリスト構造の参照と更新も同様です。<List10>
# 多重リスト(3次元)の参照と更新
#--------------------------------------------------------------------
# 元のリスト
list_b = [[["a", "b"], ["c", "d"]], [["e", "f"], ["g", "h"]]]
print(list_b) # >>[[['a', 'b'], ['c', 'd']], [['e', 'f'], ['g', 'h']]]
#---------------------------------------------------------------------
# 親要素の参照
print(list_b[0]) # ➀_1>> [['a', 'b'], ['c', 'd']]
print(list_b[1]) # ➀_2>> [['e', 'f'], ['g', 'h']]
#---------------------------------------------------------------------
# 子要素の参照
print(list_b[0][0]) # ➁_1>> ['a', 'b']
print(list_b[0][1]) # ➁_2>> ['c', 'd']
print(list_b[1][0]) # ➁_3>> ['e', 'f']
print(list_b[1][1]) # ➁_4>> ['g', 'h']
#---------------------------------------------------------------------
# 孫要素の参照
print(list_b[0][0][0]) # ➂_1>> a
print(list_b[0][0][1]) # ➂_2>> b
print(list_b[0][1][0]) # ➂_3>> c
print(list_b[0][1][1]) # ➂_4>> d
print(list_b[1][0][0]) # ➂_5>> e
print(list_b[1][0][1]) # ➂_6>> f
print(list_b[1][1][0]) # ➂_7>> g
print(list_b[1][1][1]) # ➂_8>> h
#---------------------------------------------------------------------
# 親要素の更新
list_b[0] = [1, [2, 3]]
print(list_b) # ➃>> [[1, [2, 3]], [['e', 'f'], ['g', 'h']]]
# 子要素の更新
list_b[1][1] = 4
print(list_b) # ➄>> [[1, [2, 3]], [['e', 'f'], 4]]
# 孫要素の更新
list_b[1][0][1] = 5
print(list_b) # ➅>> [[1, [2, 3]], [['e', 5], 4]]親要素の更新
➃》[[1, [2, 3]], [[‘e’, ‘f’], [‘g’, ‘h’]]]
子要素の更新
➄》[[1, [2, 3]], [[‘e’, ‘f’], 4]]
孫要素の更新
➅》[[1, [2, 3]], [[‘e’, 5], 4]]
ここまでは、個々の要素の番地(配置)をインデックスで指定する方法について取り上げましたが、番地範囲のいくつかの要素をまとめて指定ができる「スライス」という記述スタイルもあります。
次項ではこのスライスについて解説します。
2.3 スライスによるリストの参照
これまでに、リストの要素へのアクセス手段として個別の要素に対してインデックスを指定してきました。Pythonには「スライス」というインデックスの記述しタイルもあって、複数の要素を一括指定してアクセスすることもできます。
「スライス」の書式は次の通りで、アクセスした要素の範囲を、「開始位置」と「終了位置」の間に「:」(コロン)を挟んで指定します。「開始位置」と「終了位置」は省略することができ、省略した場合は、それぞれ「先頭から」「末尾まで」または、「全要素」となります。また、負数で末尾基準(末尾を-1とする)となるのは、これまでのインデックス指定の場合と同様です
➀.リスト名[開始位置:終了位置]
➁.リスト名[開始位置:終了位置:ステップ]
スライスにはステップ指定の有無により2つの書式があります
➀はステップさせない場合、➁はさせる場合です
引数1: 開始位置: 開始位置のインデックス(省略可能)
引数2: 終了位置: 終了位置のインデックス(省略可能)
引数3: ステップ: 範囲内のステップ数(増分値)の指定(省略可能)
※引数1~3はいずれも省略した場合は、全ての要素が対象になります。
戻り値: 抽出した新たなリスト
「引数3:step」では、範囲内におけるステップ幅を指定することができます。
戻り値は、要素そのものではなく指定範囲を要素とした、新たなListオブジェクトが戻ります。
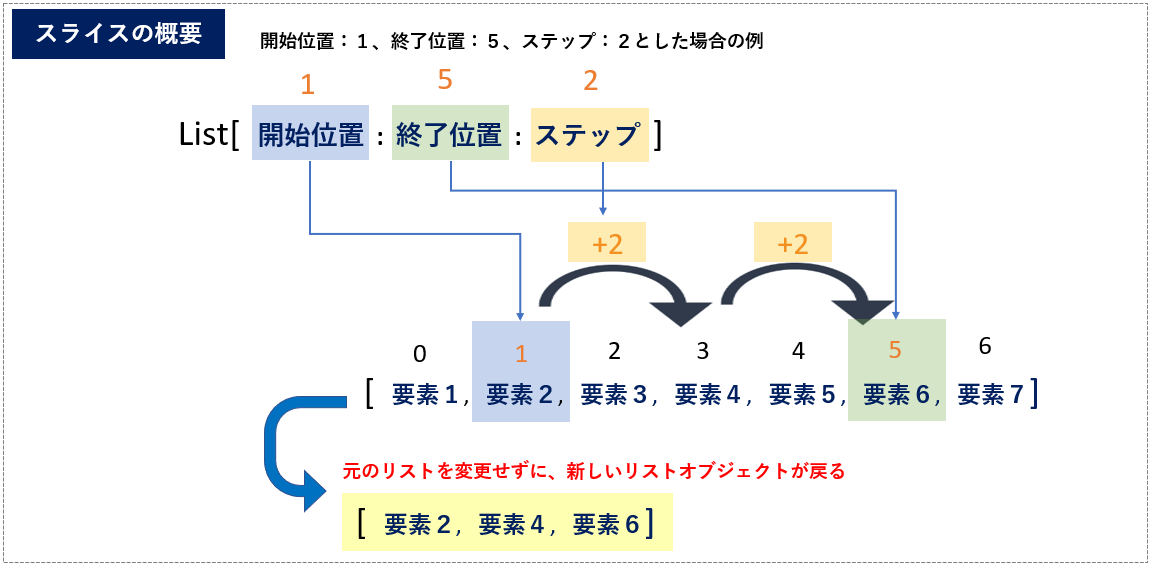
それでは、具体例をコードで確認してみます。
例1.インデックスを先頭基準(先頭を0)にして参照する例です。
開始位置を省略([:終了位置])すると先頭の要素から参照、終了位置を省略([開始位置:])すると末尾の要素まで、両方省略した場合([:])は全要素を参照することになります。
# スライスによるリストの参照(インデックスの前方基準)
words = ["blue", "red", "green", "yellow", "pink", "black", "white"] # 元のリスト
#-------------------------------------------------------------------------------------
# 開始・終了位置を省略した場合は、「要素全てを抽出」
print(words[:]) # ➀>> ['blue', 'red', 'green', 'yellow', 'pink', 'black', 'white']
# 終了位置を省略した場合は末尾までが範囲 「インデックス3~末尾迄の要素」
print(words[3:]) # ➁>> ['yellow', 'pink', 'black', 'white']
# 開始位置を省略した場合は先頭からが反に 「先頭~インデックス3の要素」
print(words[:3]) # ➂>> ['blue', 'red', 'green']
# インデックス3~5の間の要素
print(words[3:5]) # ➃>> ['yellow', 'pink']
#-------------------------------------------------------------------------------------
# 元のリストはそのまま変更されることはない
print(words) # ➄>> ['blue', 'red', 'green', 'yellow', 'pink', 'black', 'white']例2.インデックスを末尾基準(末尾を-1)にして参照する例です。
# スライスによるリストの参照(インデックスの後方基準)
words = ["blue", "red", "green", "yellow", "pink", "black", "white"] # 元のリスト
#-------------------------------------------------------------------------------------
# 最後の要素
print(words[-1:]) # ➀>> ['white']
# 最後から2番目~最後の要素
print(words[-2:]) # ➁>> ['black', 'white']
# 最後から3番目~最後の要素
print(words[-3:-1]) # ➂>> ['pink', 'black']
# 最後の要素を除く全ての要素
print(words[:-1]) # ➃>> ['blue', 'red', 'green', 'yellow', 'pink', 'black']例3.次はステップ数を指定した場合の例です。例1,2のように抽出範囲を決めてから、その次にその範囲の中から何個飛ばし(ステップ幅)で参照するのかを指定します。ステップ数に 2 を指定すると1個飛ばしとなります。(1 ではステップを省略した場合と同じ扱いとなります。)
# スライスによるリストの参照(ステップを指定した場合)
letters = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j" ] # 元のリスト
#-------------------------------------------------------------------------------------
# 先頭から末尾まで1個飛ばしの要素を抽出
print(letters[::2]) # ➀>> ['a', 'c', 'e', 'g', 'i']
# 2番目の要素から末尾まで1個飛ばしの要素を抽出
print(letters[1::2]) # ➁>> ['b', 'd', 'f', 'h', 'j']
# 2番目の要素から8番目の要素まで1個飛ばしの要素を抽出
print(letters[1:7:2]) # ➂>> ['b', 'd', 'f']
#-------------------------------------------------------------------------------------
# ステップ数に1を指定すると、stepを省略した結果と変わらない
print(letters[::1]) # ➃>> ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']以上が、リストの更新と参照についての解説となります。リストは他言語の配列のような使われ方をする場合があります、Python特有のインデックス指定方法を確認しておきましょう。
次節では、リストの連結とリストオブジェクトの比較について解説します。
3. リストの連結

2つの異なるリストオブジェクトを「連結」して新たなリストを生成することができます。Pythonでは、リスト(配列)を簡単に繋げることができます。ここでは、演算子を使った連結とメソッドや関数をつかった連結方法について説明します。
3.1 演算子でリストを連結する
複数のリストを連結させるには +演算子 を使います。2個3個…と制限なく連結させることができます。また、通常の算術演算子のように 代入演算子+= を使うこともできます。
# +演算子, +=代入演算子を使ったリストの連結
#--------------------------------------------------------
# +演算子によるリストの連結
# ➀ +演算子でリストを連結(後置)
list_a = ['a','b','c']
list_a = list_list + [1, 2, 3]
print(list_a) # >>['a', 'b', 'c', 1, 2, 3]
# ➁ +演算子でリストを連結(前置)
list_a = [4, 5, 6] + list_a
print(list_a) # >>[4, 5, 6, 'a', 'b', 'c', 1, 2, 3, 1, 2, 3]
# ➂ 連結できるリスト数に制限はない
list_b = [1, 2] + ['a', 'b'] + [3, 4] + ['c', 'd']
print(list_b) # >>[1, 2, 'a', 'b', 3, 4, 'c', 'd']
#--------------------------------------------------------
# ➃ +=代入演算子によるリストの連結
list_c = []
list_c += ['abc']
list_c += ['efg', 1, 2, 3]
print(list_c) # >>['abc', 'efg', 1, 2, 3]+演算子によるリストの連結
➀》[‘a’, ‘b’, ‘c’, 1, 2, 3]
➁》[4, 5, 6, ‘a’, ‘b’, ‘c’, 1, 2, 3, 1, 2, 3]
➂》[1, 2, ‘a’, ‘b’, 3, 4, ‘c’, ‘d’]
+=代入演算子によるリストの連結
➃》[‘abc’, ‘efg’, 1, 2, 3]
また、2つのリストを繋げるのではなく、要素を複製して末尾に追加していく *演算子 もあります。
リストオブジェクト*Nのようにします。(Nは複製・追加する数を指定する) 以下は、演算子をつかった例を示します。
# 同じ要素が繰り返し入ってくるリストを作る
# 0の要素を10個もつリストをつくる
nums = [0]*10
print(nums)
# >> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# "xyz"の要素を10個もつリストをつくる
strs = ["xyz"]*5
print(strs)
# >> ['xyz', 'xyz', 'xyz', 'xyz', 'xyz']
# 1, 2, 3の組合せの要素を3つもつリストをつくる
data = [1,2,3]*3
print(data)
# >>[1, 2, 3, 1, 2, 3, 1, 2, 3]演算子を用いた連結は、元のリストはそのままに、新規リストオブジェクトとして生成されます。
3.2 リストオブジェクトのメソッドによる連結
リストオブジェクトには、連結させるための extend()メソッド も提供しています。「extend()メソッド」は引数に、連結したいリスト(リストに限らずシーケンス型のオブジェクト)を指定します。使用例は以下のようになります。
# extend()メソッドを使ったリストの連結
data_1 = [1, 2, 3]
data_2 = ['a', 'b', 'c']
# ➀ extend()メソッドの実行(data_1にdata_2を連結)
data_1.extend(data_2)
print(data_1) # >>[1, 2, 3, 'a', 'b', 'c']
data_1 = [1, 2, 3] # 元リストの初期化
# ➁ extend()メソッドの実行(data_2にdata_1を連結)
data_2.extend(data_1)
print(data_2) # >>['a', 'b', 'c', 1, 2, 3]extend()メソッドの実行
➀》[1, 2, 3, ‘a’, ‘b’, ‘c’]
➁》[‘a’, ‘b’, ‘c’, 1, 2, 3] ※ 一つづつ要素として追加される
似たような機能のメソッドに、append()メソッド があります。先の「extend()メソッド」とは連結するユニットが異なります。「extend()」は、シーケンス型のオブジェクトから要素を一つづつコピーして、末尾に追加してくイメージですが、「append()」は、オブジェクトごと構成を保ったままのコピーを追加してくイメージです。
# append()メソッドとの違い
data_1 = [1, 2, 3]
data_2 = ['a', 'b', 'c']
# append()メソッドの実行(data_1にdata_2を追加)
data_1.append(data_2)
print(data_1) # >>[1, 2, 3, ['a', 'b', 'c']]append()メソッドの実行
》[1, 2, 3, [‘a’, ‘b’, ‘c’]] ※ 1つの要素にまとめられて追加される
メソッドによる連結の操作は、そのオブジェクト自身の要素内容に変更を加えて、更新することになります。その点は、演算子の連結とは異なりますので注意してください。(図7)

append()メソッドについてはこちら を参照してください。
4. リストオブジェクトの比較

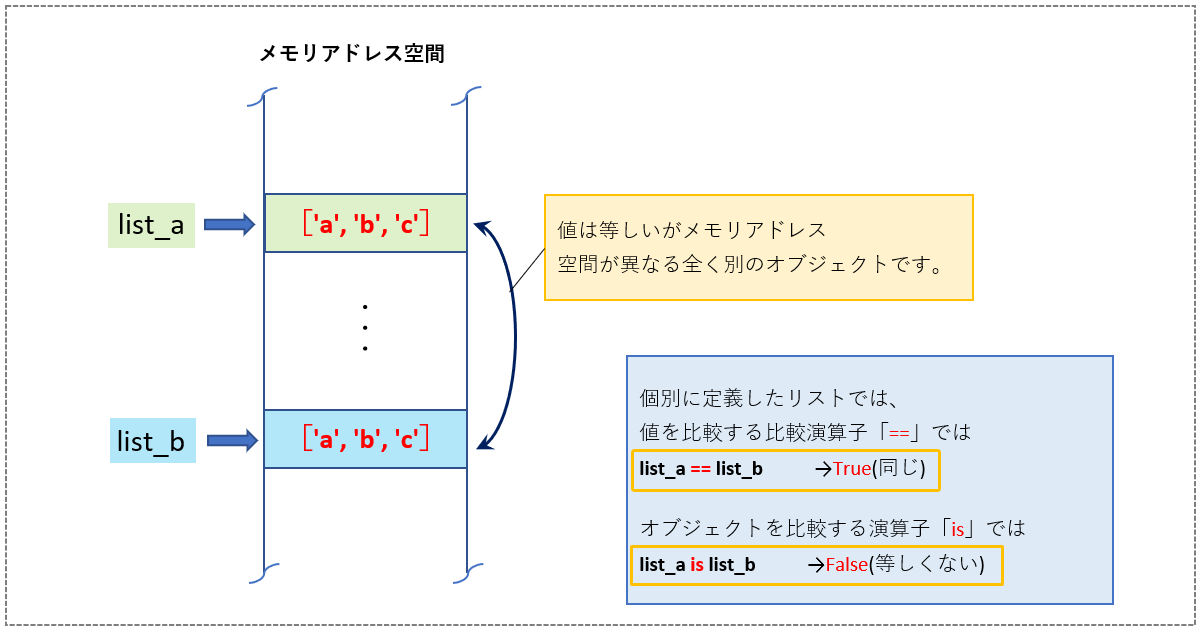
リストオブジェクトの比較(メモリアドレス上の関係)について解説します、例として次のように全く同じ要素をもつ2つのリスト(list_aとlist_b)があったとします。この2つを比較演算子「==」で評価すると当然ですが同じ(True)という結果が戻ります。<List19> (1)
今度はオブジェクトとして比較してみます、オブジェクトの比較には演算子「is」を使います。今度は2つは別オブジェクトであることを示す(False)が結果として戻りました。<List19> (2)
# リストオブジェクトの比較
# 値(要素)が全く同じリストオブジェクトを定義
list_a = ['a', 'b', 'c']
list_b = ['a', 'b', 'c']
# (1)----------------------------------------------------------
# 値の比較する演算子「==」ではTrueとなり等しいと判定
print(list_a == list_b) # >>True
# (2)----------------------------------------------------------
# オブジェクトを比較する演算子 「is」ではFalseとなり等しくない
print(list_a is list_b) # >>False
# オブジェクトのIDは不一致である
print(id(list_a)) # 2248836469000 (2)-1 オブジェクトID
print(id(list_b)) # 2248837134088 (2)-2 オブジェクトID
# (3)----------------------------------------------------------
# 別オブジェクトであることを確かめる
list_a.append('d') # list_aの要素に変更を加える
print(list_a) # >>['a', 'b', 'c', 'd'] (3)-1
print(list_b) # >>['a', 'b', 'c'] (3)-2 list_bにはlist_aの変更は反映されない(1) 値の比較する演算子「==」ではTrue (等しい値)
(2) オブジェクトを比較する演算子 「is」では False (オブジェクトは異なる)
(2)-1》2248836469000
(2)-2》2248837134088
(3) 同一オブジェクトであることを確かめる
(3)-1》[‘a’, ‘b’, ‘c’, ‘d’]
(3)-2》[‘a’, ‘b’, ‘c’] ※ list_bには、list_aの変更が反映されない
この関係を図示すると次のようになります(図8)。list_a, list_bは値は同じだがメモリ空間上は全くことなる別オブジェクトということになります。
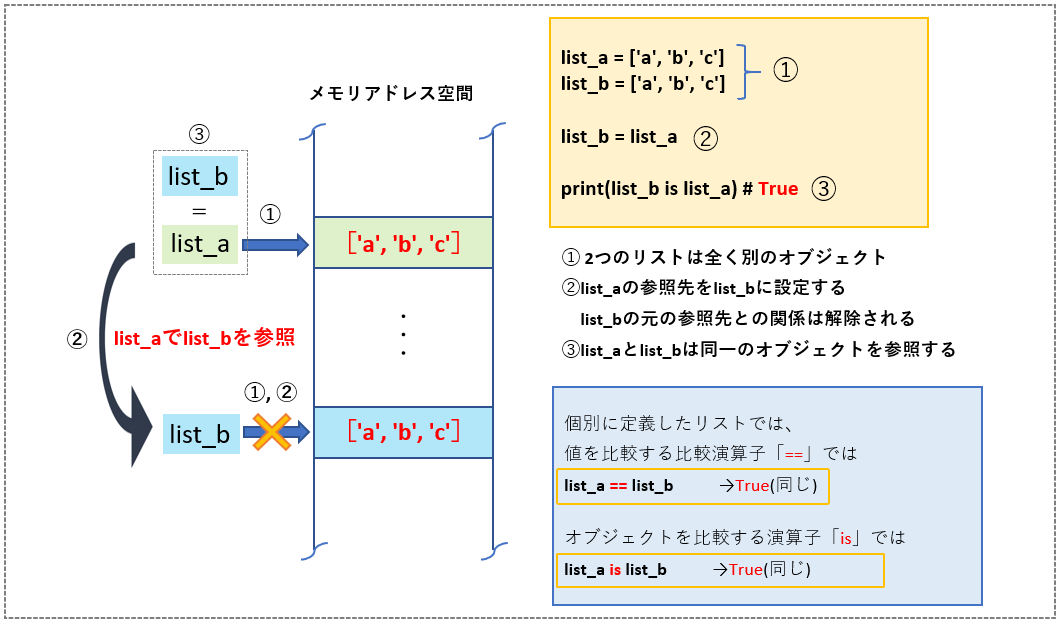
list_a, list_b両者が同じオブジェクトを指すようにするには「list_b = list_a」といったように参照先を同じにする必要があります。今度は値もオブジェクトも同じだということが確かめられました。<List20> (1),(2)
ただし、オブジェクトが同じということは片方の要素を変更した場合は、同じ参照先を指していいるもう片方のリストの内容も変更されてしまいます。<List20> (3)
したがって、オブジェクトを共有する場合はこの点を気を付けて使う必要があります。
# リストオブジェクトの比較
# 値(要素)が全く同じリストオブジェクトを定義
list_a = ['a', 'b', 'c']
list_b = list_a # list_aの参照先をList_bと共有する
# (1)----------------------------------------------------------
# 値の比較する演算子「==」ではTrueとなり等しいと判定
print(list_a == list_b) # >>True
# (2)----------------------------------------------------------
# オブジェクトを比較する演算子 「is」ではTrueとなり等しいと判定
print(list_a is list_b) # >>True
# オブジェクトのIDは一致する
print(id(list_a)) # 2248838681480 (2)-1 オブジェクトID
print(id(list_b)) # 2248838681480 (2)-2 オブジェクトID
# (3)----------------------------------------------------------
# 同一オブジェクトであることを確かめる
list_a.append('d') # list_aの要素に変更を加える
print(list_a) # >>['a', 'b', 'c', 'd'] (3)-1
print(list_b) # >>['a', 'b', 'c', 'd'] (3)-2 ※list_bにもlist_aの変更が反映される(1) 値の比較する演算子「==」ではTrue (等しい値)
(2) オブジェクトを比較する演算子 「is」でも True (同一のオブジェクト)
(2)-1》2248838681480
(2)-2》2248838681480
(3) 同一オブジェクトであることを確かめる
(3)-1》[‘a’, ‘b’, ‘c’, ‘d’]
(3)-2》[‘a’, ‘b’, ‘c’, ‘d’] ※ list_bにもlist_aの変更が反映される
この関係を図示すると次のようになります。(図9)
リスト同士を「=」で割り当てることで、値は勿論のこと、オブジェクトそのものも同じものを「指す」ことになります。
- list_a == list_b ⇒ True (同じ値)
- list_a is list_b ⇒ True (同じオブジェクト)
以上、データ構造List(リスト)の基本編として、「定義する(生成)」「参照・更新する」「連結する」「リストオブジェクトの比較」について解説しました。
5. リスト以外の配列(array, ndarray)
最後に、補足としてPythonで配列を扱う際にリスト<List>とよく対比されるデータ型についてまとめます。
<Arrayモジュール>
Pythonには、標準モジュールとして「array」が用意されています。いわゆる、他言語でいうところの「配列」に該当します。使い方は、コードの冒頭でarrayモジュールをインポートし array.array() でArrayオブジェクト(配列)を生成します。<List21>
リストとの相違点は以下の通りです。
- 同じ型しか格納できない(データ型の混載ができない)
- 1次元配列のみ
- リストと同様に、インデックス指定や組込み関数を適用できる
import array
arr_int = array.array('i', [0, 1, 2])
print(arr_int)
# >>array('i', [1, 2, 3])
arr_float = array.array('f', [0.0, 0.1, 0.2])
print(arr_float)
# >>array('f', [0.10000000149011612, 0.20000000298023224, 0.30000001192092896])<Ndarrayモジュール (NumPy)>
配列にはもう一つ外部ライブラリとして<Numpyライブラリ>のデータ型であるNdarray(Number-Dimension-array)があります。別途インストールが必要ですが、Anacondaディストリビューションに同梱されています。使い方は、冒頭でnumpyモジュールをインポートし numpy.array() でNdarrayオブジェクト(配列)を生成します。<List22>
リストとの相違点は以下の通りです。
- 同じ型しか格納できない(データ型の混載ができない)
- 多次元配列の表現可能
- 数値計算を得意とし行列や画像処理、科学計算に特化したメソッドや関数がある
- インデックスやスライスの指定ができる
import numpy as np
ndarr_1d = np.array([1, 2, 3])
print(ndarr_1d)
# >>[1 2 3]
ndarr_2d = np.array([[1, 2, 3], [4, 5, 6]])
print(ndarr_2d)
# >>[[1 2 3]
# >> [4 5 6]]通常Pythonで配列を扱う場合は、機能面ではリスト<List>で十分です。
処理速度やメモリサイズ(アドレス)を気にするのであれば、型の統一がなされる「array」や「NumpyのNdarray」の利用が選択肢として挙がります。また、機械学習や画像処理といった特定の分野ではNdarrayを業界標準として利用しています。
6. まとめ

いかがでしたでしょうか?
今回は、リストの具体的な使い方として参照と更新、連結・比較について解説してきました。繰り返しとなりますが、Pythonでのデータのやり取りにはリストは必須です。
リスト以外もに、タプル(内部リンク)や辞書(内部リンク)といったデータ構造もありますが、もっとも扱いやすく・制約なく(自由度が高い)使えるため活用頻度が高いです。
最後に、ポイントをまとめるておきます。
- リストを定義するには、[] や list()関数 を利用する。
- リストの参照・更新には、個別要素をインデックスで指定できるし、スライスで範囲指定することもできる。
- リストの連結には、演算子(+, *) や extend()メソッド を利用すると効率的に対応できる。
- リストオブジェクトの比較には「値」同士または、「オブジェクト」同士の比較がある。前者は「==」演算子、後者は「is」演算子で判定する。同じオブジェクトとなるには、同じメモリアドレスを指す必要があり、オブジェクト間を「=」で割り当てる必要がある。
さて、リストオブジェクトにはその配下に「メソッド」がいくつか用意されています。今回は、<3.2項>でextend(), append()メソッドについて少し解説しましたが、それ以外にも「要素を任意の位置に挿入する」「特定の要素を抜き取る」「並び替える」といったものもあります。
次回は、応用編として、リストオブジェクトが提供するメソッドについて整理したいと思います。リンクは以下にありますのでこちらも是非参考になさって下さい。
今回の記事を是非、お役立てくださいますと幸いです。
最後までお読みいただきありがとうございました。